


Choosing and Specifying Endpoints and Outcomes
Section 5
Using Death as an Endpoint
Prevention of death through therapeutic intervention is often a major focus of clinical research. At the individual patient level, death is the hardest of the "hard" or objectively measurable endpoints. In traditional explanatory trials, patient deaths are identified by site personnel, and the study's clinical events committee adjudicates types of death. However, death identification and adjudication may be more complicated with pragmatic clinical trials (PCTs) that rely on data collected from the patient's electronic health record (EHR), medical claims, self-report, or medical devices. Ascertaining if and how a patient death has occurred is considerably more complicated, especially if a patient dies outside the clinical care system (Eisenstein et al. 2019).
Since the typical United States healthcare system does not have standardized processes to ascertain patient deaths, explanatory clinical trials frequently include significant resources dedicated to collecting death data; a study coordinator may contact a family member or other proxy to schedule a study visit, or may search the internet to determine the patient's current location (Eisenstein et al. 2019). Compounding the issue, there is no timely and comprehensive national death database that efficiently links with EHR records (Eisenstein et al. 2019). This is due to differences between the types of information EHRs collect, what death databases require for linking, and state restrictions on the reuse of death data and other vital records (da Graca et al. 2013). However, for PCTs that use death as an endpoint, there are alternate procedures for obtaining death data. In this section, we describe alternative death data sources and methods for obtaining information from them. We then illustrate the use of these procedures in a hybrid death identification and verification approach that is being used in the ToRsemide compArisoN with furoSemide FOR Management of Heart Failure (TRANSFORM-HF) PCT (ClinicalTrials.gov Identifier: NCT03296813).
Sources of Death Data
Obtaining information to determine whether someone is alive or dead would seem to be a simple task. However, the reported mortality rate for a group of individuals can vary widely depending upon the death information source used and the method for ascertainment (Warren et al. 2017). As a first step in death-event identification planning, researchers should determine what data they require from the death event. This will determine the most appropriate death data source for their study, as sources of death data vary in both the amount and type of data they provide. For example, it may be sufficient to simply know the study participant has died, otherwise known as the “fact of death” (FOD) information about that decedent. This often involves a non-comprehensive death file with enough data elements to link with to determine the date of death. However, some studies will want the date of death, cause of death, and other related conditions, and perhaps occupation and educational level.
Next, researchers should consider whether a single death information source is sufficient for their needs or whether a hybrid approach that combines multiple data sources might yield better results. Factors to consider include whether one source makes the most sense for a specific study, and if multiple sources are combined, how will death discrepancies between data sources be addressed? While researchers can reason about the appropriateness of specific death information sources for a particular study, there is scant empirical data to use in making those determinations. Three national databases that should be considered are the Death Master File from the Social Security Administration (SSA), the Medicare Master Beneficiary Summary File, and the National Death Index (NDI) from the National Center for Health Statistics (NCHS). Artificial intelligence (AI), including machine learning, natural-language processing, and record-linkage techniques can supplement these sources by improving matching between clinical records and national death files, or extracting cause-of-death from unstructured data (Al-Gradi et al. 2025; Young et al. 2021). Other sources of death information are individual state vital statistics and the use of a central call center that consolidates site follow-up activities typically conducted in explanatory clinical trials. An additional recent source to consider is not a database but rather an FOD web service provided through the nonprofit National Association of Statistics and Information Systems (NAPHSIS).
The Federal-State Relationship in Collecting Vital Records
A brief overview of the process that produces vital event data and statistics is a useful introduction to explaining the nuances of who “owns” the data and why it is so challenging to have a single, timely, and complete national file available for adjudication of vital status.
The United States has always had a highly decentralized federal vital statistics system. Collection of vital statistics in the United States is a state function rather than a federal function. The reason is due both to how vital record collection evolved, and also to the legal situation: because the collection of these data is not explicitly outlined as a federal responsibility in the Constitution, federal authority in directly conducting this process is limited. On a practical level, the local nature of vital event registration is most likely due to its origins as a local government function and because it would have been impossible to undertake the process efficiently at a federal level until the advent of modern technologies. The civil registration of births, deaths, and marriages is one of the oldest systematic collections of data in the United States. Births, deaths, and marriages were a civil registration function in the Commonwealth of Virginia as early as 1632. The modern era of systematic registration of vital events began in 1842 in Massachusetts with passage of the first law requiring statewide registration of vital events. Since 1933, all states and territories have required registration of vital events. Since then, the registration of vital events has broadened to include not only civil registration but also the collection of public health data. More recently, vital records offices have the added responsibility of helping to ensure national security through the effective stewardship of birth certificates (National Research Council 2009).
Today, vital event data reported to the federal government includes data on birth, death, and fetal death events. Although local vital record offices also collect data on marriages and divorce, the federal government stopped routine collection of this information in 1995. The NCHS is charged with collecting and aggregating these data at the federal level. Since vital event registration happens at a local level, the NCHS obtains data from local registrations through the Vital Statistics Cooperative Program (VSCP), which pays each state/territory for its data. Each jurisdiction has a VSCP agreement with NCHS to provide data according to NCHS national standards for quality and timeliness (National Research Council 2009).
There are a number of challenges with national aggregation of vital statistics. One of these is timeliness. Vital statistics compiled centrally at the national level can only be as timely as the latest state. Many states have implemented electronic systems but not fully. As of June 2018, NAPHSIS reported 46 jurisdictions with an electronic death registration system (EDRS), but only 39 had over 75% of the death events registered through an EDRS. Another limitation is the need to ensure state laws governing the release of vital records are honored by federal agencies that receive these data. The redaction from the death master file, explained in more detail below, is the result of this legal constraint. Another challenge is ensuring a high degree of data quality in a process that involves 57 separate jurisdictions, with those using electronic data capture systems rarely using the same system. The public health aspects of data collection are perhaps the most challenging as they often involve a clinical provider. The vast majority of clinical providers use EHRs today. Yet, integration between EHRs and electronic vital record systems is rare. A handful of states have enabled integration of an EHR with their EBRS. As of June 2018, only two states (California and Utah) had demonstrated an integration between their EDRS and an EHR. The California experience showed relatively high implementation costs for health systems (>$50,000 to start), which could be a significant barrier to broader adoption. Furthermore, when it comes to deriving the important “cause of death,” the process is not immediate, and in 25% of the cases requires a manual review and adjudication by a trained nosologist. There is only one cause of death for the decedent. Think of it as "classifying" the death into only one cause, or assigning it a single code from the International Classification of Diseases (ICD). In order to accomplish this, the model death certificate in the United States has four blocks of narrative text known as the “underlying causes of death.” The medical certifier uses these to outline the cascade, or sequence, of events that resulted in the death. The NCHS uses a semi-automated process to classify the single "cause of death" in the NDI database based on the information on the death certificate. The national file that includes cause of death is not complete until all the deaths have been classified for the reporting time period, typically a calendar year.
Death Master File
To administer its programs, the Social Security Administration (SSA) collects death information from family members, funeral homes, financial institutions, postal authorities, states, and federal agencies. Prior to 2011, the SSA Death Master File (DMF) was the timeliest, most comprehensive, and least expensive method for obtaining patient death data (da Graca et al. 2013). However, in 2011, the SSA agreed with closed record, stating that §205(r) of the Social Security Act (SSA 1983) could not supersede state laws limiting disclosure of the state records. This resulted in the removal of 4 million records (5%) and in the annual exclusion of 1 million new files (40% of new deaths) from the DMF (National Technical Information Service 2011; da Graca et al. 2013). While the public DMF does not contain death data received from states, it still includes information obtained from other sources and remains a valuable death data resource for researchers. Potential users can apply to the certification program and pay an annual subscription fee for access to the files. Alternatively, DMF data are commercially available, in whole or in part, in services such as Ancestry.com and Legacy.com. When using the DMF, researchers should be aware that these death records are incomplete. A recent analysis compared the DMF to Medicare and commercial insurance databases and demonstrated that the DMF markedly underestimated mortality rates (Navar et al. 2019). This under-capture of death data varied significantly overtime and between states, leading the authors to conclude that “Researchers should avoid relying on mortality estimates based on the SSDMF alone and be aware of heterogeneity in SSDMF data completeness” (Navar et al. JAMA Cardiology 2019). The implication is that while DMF deaths are actual deaths, the absence of a DMF death does not mean that a patient is alive.
Medicare Master Beneficiary Summary File
If a substantial number of study patients are Medicare beneficiaries, the Medicare Master Beneficiary Summary File may be an option for obtaining death data. This file includes death information received from Medicare claims, family member online date of death edits, and Medicare benefits information collected from the Railroad Retirement Board and the SSA. This file is available from the Research Data Assistance Center (ResDAC) with a 9-month lag from the close of the calendar year (da Graca et al. 2013). The standard linking approach relies on direct identifiers—Social Security /Health Insurance Claims number (Medicare ID number), date of birth, and sex. In the past, ResDAC also has allowed the use of deterministic linkage approaches based on dates of service (Hammill et al. 2009). Researchers should be aware that Medicare Master Beneficiary Summary File death records only include people with a Medicare beneficiary number. This means that the absence of a death in this file does not mean that a non-Medicare patient is alive.
State Vital Statistics
Only states have the authority to collect birth and death data, and they typically collect this information through vital records offices within departments of public health. The process of registering the death event has both legal and epidemiological components and involves at least six separate sources of information, making it a complex process often not well understood outside the confines of the small public health vital statistics community. Coroner cases are more complex and involve additional sources of information including a coroner (law enforcement) and a forensic pathologist. Some states, like California, have made the vital statistic process entirely digital and accept applications for public use birth and death files. California has two types of death files available. The Comprehensive Death File requires review and approval by the California Vital Statistics Advisory Committee (VSAC) and includes a substantial amount of data, including cause of death, Social Security number, etc. The California non-comprehensive death file is an FOD file and includes deaths from 2005 to present. The death data has a short lag time (85% of deaths are less than 30 days old when included in the file, 96% of deaths are less than 60 days old). The cost is minimal ($400 per year). California does not include a Social Security number in the non-comprehensive death file, as the statute regarding public release of death information prohibits it. Depending on the number and location of sites in a clinical trial, the use of state vital statistics, alone or in combination with another death data source, may be a viable option for obtaining death endpoint data. However, information from more than one state may be necessary to detect the death of a patient who resided in one state and died in another. Researchers should be aware that state vital statistics death records are incomplete and only contain information for deaths occurring in that state. This means that the absence of a death in a state death file does not mean that a patient is alive.
NAPHSIS EVVE Fact of Death (FOD) Service
The NAPHSIS FOD service is not a database but instead a secure online web service derived from a service originally developed to verify birth certificates. Birth certificates are often required to be presented for benefit eligibility, and origination of key identification documents (driver’s licenses, Social Security cards, passports, etc.). NAPHSIS electronic verification of vital events (EVVE) allows a state agency office in one state to verify a birth certificate being presented by the applicant from another state. NAPHSIS extended this service to provide fact of death querying based on death certificate data from participating states. A key aspect of the NAPHSIS EVVE system is that it is a distributed querying system that directly accesses vital records databases of participating states on demand, so it is using the most current information for each state. The SSA DMF, Medicare Master Beneficiary Summary File, and the Centers for Disease Control and Prevention's NDI have varying degrees of latency, or “lateness,” because they must aggregate data from all the states into a single centralized system, which can make the databases anywhere from 6 to 36 months behind when the death events occurred. State files like the California non-comprehensive file are timelier but still have a lag time of around 15 to 30 days. Although the NAPHSIS EVVE FOD does not have the 6- to 36-month aggregation time lag, not all states participate. As of 2025, 44 of 57 jurisdictions were part of the EVVE FOD. Pricing from 2018 for nongovernmental use varies and is based on volume. For example, submitting 5000 to 10,000 records to the service costs $3000, or $1.60 per record. A query with 1 million records costs $10,000, or $0.01 per record. It is important to note that although this is the timeliest source of death data, it is only fact of death information, and some states (including California) do not participate.
National Death Index
The Centers for Disease Control and Prevention’s NCHS contracts with state vital statistics offices to receive and compile annual death registries in the NDI, a centralized database of all US deaths. The mission of NCHS is to help guide public health and health policy decisions and to “aid health and medical investigators with their mortality ascertainment activities” (NCHS). This service does not allow access to the public or organizations for legal, administrative, or genealogy purposes. The NCHS only allows use of the NDI for mortality determination in qualifying research studies. Use for administrative purposes is not allowed. This is not the result of statutory restriction, but rather because of how the NDI has evolved. The NDI is not provisioned by law nor is it funded through Congressional appropriation. Instead, the NDI is the result of over 40 years of trust building between the 57 federal jurisdictions and the NCHS (Dr. Charles Rothwell, personal communication). The agreed-upon process and use has been acceptable to all 57 jurisdictions under the existing research-only use model, which is also an accepted use in every jurisdiction. NCHS is, in essence, an “honest broker,” trusted by the 57 jurisdictions to use their data to support research studies in any jurisdiction. This is key in ensuring the NDI has all the deaths nationally and is a complete data set. Broadening the use of the NDI beyond the research-only scope would invariably bring it into conflict with states that have restrictive laws on the use of these data, thus leading to redactions and an incomplete data set. What has been acceptable to all 57 jurisdictions has been tightly controlled use for research vital status adjudication. The NDI service is self-supporting through fees, which have portions of revenue allocated back to the state/territory jurisdictions that provision the data. Unlike the other death data sources listed above, the NDI is a complete death data set. All jurisdictions report all deaths to the NCHS, which makes the NDI the most complete death data set available in the United States today. The implication is that NDI deaths are actual deaths and the absence of an NDI death means that a patient can be considered alive at the end of the reporting year. This distinction becomes important when determining a study subject’s last known status (ie, dead or alive).
NDI Cause of Death
NDI Plus reports patient cause of death using death certificate information. However, this information is not always reliable (Lauer et al. 1999). Death determination can be inexact due to low patient autopsy rates and complex medical conditions. Physicians typically receive no training in completing death certificates and often confuse the mechanism of death (e.g., cardiac arrest) with the underlying cause of death (e.g., cancer). Lloyd-Jones and colleagues compared cause of death information from death certificates with that adjudicated by a panel of three physicians (Lloyd-Jones et al. 1998). These researchers found that coronary heart disease as the cause of death was 24% greater on death certificates versus physician panel adjudications. They also found that this error rate increases with patient age.
Using the NDI
To gain access to the NDI, potential users submit an application form along with a current Institutional Review Board (IRB) approval document. There is an approximate 2- to 3-month review period. Once the application is approved, investigators are not granted direct access to the database but rather submit study subject records in a standard text file (flat file) format, using NDI’s coding specifications, on a password-protected CD-ROM or through their secure File Transfer Protocol (sFTP) site. The investigator will receive a password-protected CD-ROM or staff will return the information through the sFTP with potential death matches for the investigator to verify.
Beginning January 1, 2020, the NIH will reimburse the National Center for Health Statistics (NCHS) National Death Index (NDI) for the cost of NIH-supported investigators linking their research databases to the NDH. To be covered by this agreement, the NIH-supported researcher must be the owner or steward of the data being linked to the NDI datafile. Investigators are limited to four linkage requests per calendar year, and linkage requests exceeding $100,000 require pre-approval by the NIH. NCHS will be implementing an improved online application and will increase the frequency of NDI releases to quarterly. NDI permits full deidentified research datasets with NDI-linkage to be shared without further NDI approval. Datasets with potentially re-identifiable data may also be shared if the dataset is not transferred from one owner to another.
The fees for using the NDI as of October 2025 were as follows:
- $350 for the first search and $100 for each subsequent search
- Routine search is $0.15 per unique patient per year being searched
- NDI Plus search (which adds cause of death) is $0.21 per unique patient per year being searched
- Known death search is $5 per patient regardless of how many years searched
NCHS provides a worksheet for calculating charges. Depending on the number of patients enrolled in a trial (many PCTs enroll tens of thousands of patients) and the number of years for follow-up, use of the NDI can be expensive.
Sample Worksheet for NDI Fees

Source: Screen shot from the worksheet for calculating National Death Index Charges. Available at: https://www.cdc.gov/nchs/data/ndi/ndi_user_fees_worksheet.pdf
Time Lag for NDI Data
Deaths are submitted electronically by states to NCHS throughout the calendar year. Death records are added to the NDI database (in a batch) after the end of each calendar year. An early release file is made available for both NDI Routine and NDI Plus searches when approximately 90% of the (previous) year's death records have been received and processed. NDI data releases can be delayed (e.g., COVID pandemic), but are typically available for investigator search requests in late January or early February and are considered preliminary. Additional deaths can still be added, and demographic variables (such as age) are subject to change. At the time of this file’s internal release, the NCHS also provides a summary table showing the completion rate by state so that studies can decide whether they should use the preliminary search. Note that although the CDC uses the nomenclature “early release” and “final file,” these files are not available for downloading, they are available for matching the records of submitted files using the application process described in the "Using the NDI" section.
NDI Early Release File – Vital Status Reporting Completion Status Sample Summary Table.
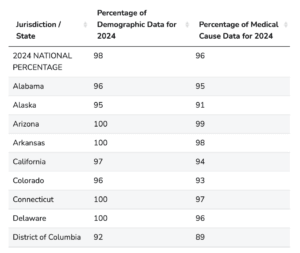
Note: The second column reflects cause of death data, which are included in an NDI Plus search. (Full table available at https://www.cdc.gov/nchs/ndi/completion_status.htm. Screen shot taken October 31, 2025.)
The final file reflects “all” of the (previous) year’s death records. This file is available in late October or early November. Once the final file for a given year is available, users of the early release file can submit the same records for one free rerun search, provided that all parameters are identical to the original early release search and submitted within 6 months of notification that the final file is available. The final file is static and won’t be modified unless there was a serious error; for example, about 125 records from Tennessee and Massachusetts were modified in the 2014 death final file. The cause of death was changed from “unspecified external” cause of death to either “suicide” or “homicide.” In this example, studies were allowed to resubmit their “true matches” from 2014 to obtain the corrected cause of death at no cost.
Is Final Really Final?
Belated records do exist. For example, a death in 2014 deemed a suicide may be disputed by family members and therefore not released to the NCHS for inclusion in the NDI until 2016.
However, the 2014 Final Death File would not be modified to include that death. Instead, it would show up in the 2016 file (released in 2017) with a date of death in 2014. Bottom line: once a year’s death records have been searched in the final file, there is no need to repeat that year in future searches unless in rare cases of modification where the investigator would be notified by NCHS.
See Appendix for the NDI death identification and adjudication process.
Data Elements
Death data sources use different data elements for matching. This means that investigators need to ensure that adequate matching information and required patient consents are obtained during the course of the trial. For example, in the TRANSFORM-HF case example described below, the investigators used the NDI that requires more detailed Asian race categories than typically are reported for clinical trials. These investigators also decided to obtain data elements that are not required but increase the likelihood of an NDI match. These include patient marital status (using NDI categories), patient social security number, and patient middle initial. The table below compares the types of information used in searching different death data sources. Researchers should be advised that some of these data elements are optional for specific data sources and that the specific coding for data elements may differ between data sources. For this reason, researchers should consult the instructions for each data source when planning data collection for their study.
Comparison of Data Elements Used for Matching
| Data element | Death Master File | National Death Index | Medicare Master Beneficiary File | California’s non-comprehensive death file | NAPHSIS EVVE FOD |
| Social security number | x | x | x | x | |
| Beneficiary identification code | x | ||||
| First name | x | x | x | x | |
| Middle name | x | x | x | ||
| Middle initial | x | ||||
| Last name | x | x | x | x | |
| Birth date | x | x | x | x | x |
| Month of birth | x | ||||
| Day of birth | x | ||||
| Year of birth | x | ||||
| Death date | x | x | x | x | |
| Last known zip code | x | ||||
| Sex | x | x | x | ||
| Father’s surname | x | x | |||
| State of birth | x | ||||
| Place of birth | x | ||||
| Race | x | ||||
| County code | |||||
| State of residence | x | ||||
| State of death | x | ||||
| Place of death (county or state/county) | x | ||||
| Marital status | x |
*Medicare Beneficiary ID (insurance ID) can also be used for matching.
Call Centers and Research Staff
Some studies use a central call center that consolidates follow-up activities typically performed by study sites. Call centers will perform telephone interviews with patients or their proxies at regular intervals using standard procedures that enhance overall study data quality and completeness. Research staff in the call center also may perform internet searches, visit ancestry.com and other social medial sources, search for obituaries and grave markers, and contact the patient’s health care providers for patient death information.
Comparison of Sources of Death Data for use in PCTs
The table below compares different death information sources.
Comparison of Sources for Death Data
| Death Master File | National Death Index | Medicare Master Beneficiary Summary File | California Non-comprehensive | Call Center | |
| Creator | Social Security Administration | Centers for Disease Control and Prevention National Center for Health Statistics | Centers for Medicare and Medicaid | California Department of Public Health | Coordinating Center |
| Source data | Primarily from family members of the deceased when a claim is made by a beneficiary but also by funeral homes, financial institutions, and the states | Family members and funeral homes report deaths to the state. The states have monetary contracts to provide death registries annually to the NDI | Death information received from Medicare claims, family member online date of death edits, and Medicare benefits information* | Death certificates | A proxy, grave marker, ancestry.com, legacy.com, online searches, social media, obituaries, medical records, enrolling site report
|
| Cost | Subscribers pay annual fee | Per record/subscription. Can be expensive | Variable. See fee worksheet | Relatively inexpensive ($120/year) | Cost of call center |
| Lag | 4-6 months | Reporting occurs in batches at the end of a calendar. The early release file (90% accurate) is generally available in February and the final file is available by the end of the calendar year. | 9 months from the close of the calendar year | 60 days for 96% of deaths | Depends on call/follow-up schedule defined in the protocol |
| Cause of death | No | Included in an NDI plus search | No | No | No |
| Data acquisition | Researchers can run their own queries | Data on patients must be submitted and a file will be returned | ResDAC.com is a CMS-funded resource that helps researchers request data. | An FOD file includes deaths from 2005 to present | |
| Considerations | In 2011, SSA stopped reporting 40% of deaths due to HIPAA regulations (National Technical Information Service 2011; da Graca et al. 2013). | 1. Because deaths are included at the end of the calendar year, if a patient dies in January, and a researcher waits for the final file, it could involve almost a 2-year lag. 2. Depending on how many patients are involved in a trial and the follow-up duration, this method can be prohibitively expensive. | File only includes information on Medicare beneficiaries | Depending on the number of states involved in the trial, collecting the data from every state can be time consuming | Involves extra effort and cost |
*Note: This benefit information is in large part “collected from the Railroad Retirement Board (RRB) and the Social Security Administration (SSA)” (RESDAC 2018)
While the NDI will eventually report complete death data, there are reasons why a PCT may consider a hybrid approach that combines a call center with NDI searching. As an example, if a PCT participant dies in January, it potentially will be a year and a month before their death data are available in the early release file and almost two years before the data are available in the final file. If a participant dies in December, the lag to the early release file is only a month or two. This time lag can create problems for studies that rely upon NDI data and have reached the end of their follow-up period. Either they can wait until NDI reports all potential deaths for their study or they can supplement NDI with other death data sources. As an example, assume a clinical trial contacts study subjects at six-month intervals for telephone interviews. If a patient enrolls in January 2017 and the trial ends follow-up in February 2018, the NDI early release file for February 2018 deaths will not be available until early 2019 and the final file will not be available until October-November 2019; whereas death information derived from a 6- month follow-up telephone call to relative or friend will be available in August 2018. In contrast, if the patient enrolls in October 2017 and the trial ends follow-up in February 2018, the NDI early release file for a November 2017 death will be available in early 2018 and the final file in October-November 2018. In this case, a death identified in the NDI’s early release file will be available before the patient’s next scheduled telephone interview in April 2019. Due to time lags in death information availability, investigators may choose a hybrid approach that relies upon multiple death data sources. This hybrid approach may be particularly useful in an event-driven trial that ends follow-up when a prespecified number of events have occurred.
Another reason for selecting a hybrid approach is that a study may not be able to collect all information required for an NDI match. As an example, SSN is a key NDI search term, and many patients will be hesitant to share their SSN with the research study team. While the NDI can be searched without SSNs, this may lower the likelihood of finding a match. Thus, while the NDI may contain the required patient death data, the study may not have all of the information required to find the NDI match. In these instances, having a second death data source will serve to fill gaps in NDI death data searches.
TRANSFORM-HF Case Study
Use of NDI and Call Center for Ascertaining a Death Endpoint
In the ToRsemide compArisoN with furoSemide FOR Management of Heart Failure (TRANSFORM-HF) PCT (ClinicalTrials.gov Identifier: NCT03296813), pragmatic trial investigators used both the NDI and a call center for ascertaining death as and endpoint. Details of death ascertainment in TRANSFORM-HF were previously published by the authors of this chapter (Eisensten et al. 2019), and we will briefly summarize the salient aspects here.
TRANSFORM-HF is a randomized, PCT of patients hospitalized for new or worsening heart failure. The trial involved ~50 sites, and patients were individually randomized to receive a prescription for an oral diuretic (torsemide or furosemide; both are commonly prescribed) prior to hospital discharge (Greene et al. 2021).
All-cause mortality was the primary endpoint for TRANSFORM-HF, and investigators anticipated more than 720 deaths. The DCRI Call Center conducted follow-up interviews with patients at 30 days, 6 months, 12 months, and at 6-month intervals to ascertain patient status. Because the information sources used by the call center may (ie, contacting a proxy, searching for obituary acceptable grave marker, requesting medical records related to death) may be incomplete, investigators also searched NDI for patient deaths. Either method can be used to verify a patient death (Figure).
Flow Diagram for Confirmation of a Death

From: Eisenstein et al. 2019. Used with permission.
The TRANSFORM-HF study investigators considered the following Key Questions in their use of death as an endpoint. We believe these questions can be applied to other clinical trials where sites will not be responsible for identifying subject deaths and clinical events committees will not determine cause of death.
- Do we need just FOD or do we need other data such as cause of death, occupation, marital status, educational level, manner of death, etc. Could EVVE FOD be sufficient instead of using NDI?
- TRANSFORM-HF’s primary endpoint was all cause mortality. Although the FOD endpoint was the simplest death endpoint to collect, TRANSFORM-HF also required date of death for the purpose of primary endpoint statistical analysis. The Data Safety Monitoring Board also asked for cause of death data (post COVID), which was obtained from the NDI.
- If other death-related (e.g., cause or location) and non-death-related (e.g., occupation, marital status) are required, this will constrain the number of potential death data sources and may degrade the overall quality of information available to determine the death endpoint.
- How often should we submit the NDI search?
- TRANSFORM-HF’s NDI search plan was based upon the anticipated accrual of death events during the trial, and used both the early and final release files to capture death events at the earliest times they were available. TRANSFORM-HF was an event-driven trial designed to proceed until 721 patient deaths were recorded. Having early release files was helpful, as most study deaths were available shortly after the end of the calendar year.
- Since NDI data are available for specific calendar years, trials typically will conduct at least one search per year. Because of the time involved in managing NDI searches, many trials may choose only to use each year’s final release file.
- Should we search all patients or only when vital status is unknown?
- TRANSFORM-HF’s NDI search plan included all patients not matching a previous NDI search. This means that a patient with death verified by the DCRI Call Center could be included in NDI searches. This was particularly helpful in determining dates of death, as proxies may know that a patient has died, but may not know the exact date of death. This also allowed for comparison between death data accrual from the NDI versus the call center. There was substantial agreement between deaths identified by a centralized call center and the NDI. However, the time between a death event and its identification is significantly less for the call center as shown in the Figure (Eisenstein, et al. 2022).
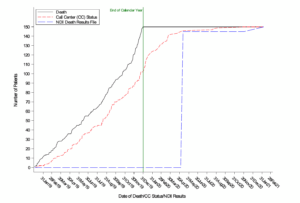
-
- Other studies may choose to eliminate patients from NDI searches when they are identified by another death data source.
- If we find a "true match" during a search, can we drop the subject from future searches?
- TRANSFORM-HF’s NDI search plan stipulated that when patients were identified as a true NDI match, they were not included in subsequent years searched.
- Since the NDI file is final for each year, there was no reason for a study to include matched patients in subsequent years searched.
- We’re only doing follow-up phone calls for a maximum of 30 months post-randomization. Should we keep doing the NDI search on the early cohort of patients even if the death file being searched is beyond 30 months from their randomization date?
- TRANSFORM-HF’s NDI search plan excluded patients from subsequent year searches who had reached their 30-month anniversary.
- Other studies may choose to extend NDI searches beyond the follow-up period as a means of obtaining long-term mortality data for their patients. However, this use of NDI data should be noted in the protocol, informed consent, and other regulatory documents.
- Similar question for the later cohorts with less follow-up time by the Call Center.
- As stated above other studies may choose to extend NDI searches beyond their follow-up period. However, this use of NDI data should be noted in the protocol, informed consent, and other regulatory documents.
- What about later cohorts with less follow-up time by the call center?
- As stated above, other studies may choose to extend NDI searches beyond their follow-up period. However, this use of NDI data should be noted in the protocol, informed consent, and other regulatory documents.
- What are the possible permutations of non-agreement between the Call Center and NDI results that we should account for?
- Most instances of non-agreement will be timing related, with one death data source identifying a death event before the other. In the TRANSFORM-HF study, there was substantial agreement between deaths identified by a centralized call center and the NDI. However, the time between a death event and its identification was significantly less for the call center (Figure) (Eisenstein et al. 2022). Both the DCRI Call Center and the NDI were needed because they served different functions. The DCRI Call Center identified death events earlier and provided real-time data (death and other) for use in monitoring study progress. The NDI searches both confirmed call center–triggered deaths and identified additional deaths not identified by the call center. If NDI searches had been the sole death data source, this could have significantly delayed study results availability and the time when patients might have benefited from their dissemination (Eisenstein et al. 2022).
- The TRANSFORM-HF’s statistical analysis plan considered both death event sources (DCRI Call Center and NDI search) as being equal. Hence, if either source identified a death event, it was accepted without verification by the other death data source.
- In situations where both data sources have had sufficient time for death event identification, there were instances when either the NDI search or the call center identified a death and the other did not. These few instances were due to incomplete information for the NDI search or deficiencies in call center death data sources (Eisenstein et al. 2022).
- Other studies will determine how to manage disagreements between different death data sources. This should occur before the study commences enrollment.
- Can we assume if a patient wasn’t found dead by the call center or NDI that they are alive?
- Positive contact by the call center can be used as evidence that the patient is alive as of the call date. However, if the call center does not verify the patient is dead, that does not mean the patient is still alive, only that the patient was alive on the last contact date.
- In contrast, if the NDI search does not identify the patient as dying in a calendar year, that patient is presumed to be alive on the last day of the calendar year.
- What will we consider the event-free censoring date for mortality given we have staggered amount of follow-up per “cohort,” call center and NDI methodology, etc.?
- Although TRANSFORM-HF subjects did not have an “end of study visit” with the enrolling sites, they were scheduled to have a final telephone visit with the DCRI Call Center. Depending upon their entry cohort, this final visit occurred at 12, 18, 24, or 30 months. This date of the final visit, if it took place, was the subject’s censoring date.
- Other studies will need to decide how to determine censoring dates for study subjects, and to consider statements made in the study protocol, as well as informed consent and other regulatory documents.
Appendix. NDI Death Identification and Adjudication Process
NDI Death identification process
- Each submitted record must contain at least one of the following combinations of identifying data elements:
- Social Security number, sex, full date of birth present
- Last name, first initial, month of birth, year of birth present
- Last name, first initial, Social Security number present
- Additional demographic variables increase the odds of a true match:
- Middle initial
- Father’s surname
- State of Birth
- State of residence
- Marital Status
- Race
Death Adjudication Process
Search Results Score
- Records are returned with a score reflecting the degree of agreement between the identifying information on the submission record and the NDI death record.
- The score is based upon probabilistic weights assigned to each of the identifying data items used in the NHIS -NDI record match (Fellegi and Sunter 1969).
Score = {ΣWSSN1 + …+ WSSN95} + Wfirstname x sex x birthyear + Wmiddleinitial x sex + Wlastname + Wrace + Wsex + Wmaritalstatus x sex x age + Wbirthdate + Wbirthmonth + Wbirthyear + Wstateofbirth +Wstateof residence
Class
- Then, each match is categorized into one of five mutually exclusive classes that take into account which identifying items agree.
- Classes reflect that some of the 12 NDI identifying items are more important for determining true matches than others (e.g., SSN versus state of birth) and that non-changing identifying information is more important than information that can change over time (e.g., birth surname versus marital status).
- As SSN is a key identifier in the matching process, each NHIS-NDI record match is initially classified according to whether SSN is:
- present and agrees (Class 1 or 2), or
- present but disagrees (Class 5), or
- missing (Class 3 or 4).
- Class 1: Agrees on at least 8 (of 9) digits of SSN, first name, middle initial (including blank), last name, birth year (+/- 3 years), birth month, sex, and state of birth.
- Class 2: Agrees on at least 7 (of 9) digits of SSN and at least 5 more of the following items: first name, middle initial (including blank), last name, birth year (+/- 3 years), birth month, sex, and state of birth.
- Class 3: SSN unknown but eight or more of first name, middle initial, last name, father’s surname (for females), birth day, birth month, birth year, sex, race, marital status, or state of birth match.
- Class 4: SSN is unknown on either the NHIS submission record or the NDI record and fewer than 8 of the items listed in Class 3 match.
- Class 5: SSN is present but fewer than 7 (of 9) digits on SSN agree.
Algorithm for Determining True Matches
1. Exclude poor matches:
– If NDI death date is before the randomization date
– If NDI score<=0
– If NDI class=5
2. Narrow down potential matches to best single match:
– Drop duplicates (i.e., match records with same death certificate)
– Select the one with the smallest value of class for the patient
– Select the one with the largest score
– Manual review in event of a tie (use importance of matching items as tiebreaker)
SECTIONS
REFERENCES
Al-Garadi M, LeNoue-Newton M, Matheny M, et al. 2025. Automated extraction of mortality information from publicly available records. J Med Internet Res. 27:e71113. doi: 10.2196/71113. PMID: 40824124.
da Graca B, Filardo G, Nicewander D. 2013. Consequences for healthcare quality and research of the exclusion of records from the Death Master File. Circ Cardiovasc Qual Outcomes. 6(1):124-128. doi:10.1161/CIRCOUTCOMES.112.968826. PMID: 23322808.
Greene SJ, Velazquez EJ, Anstrom KJ, et al. 2021. Pragmatic design of randomized clinical trials for heart failure. JACC: Heart Fail. 9:325-335. doi:10.1016/j.jchf.2021.01.013. PMID: 33714745.
Eisenstein EL, Prather K, Greene SJ, et al. 2019. Death: the simple clinical trial endpoint. Stud Health Technol Inform. 257:86-91. doi:10.3233/978-1-61499-951-5-86. PMID: 30741178.
Eisenstein EL, Sapp S, Harding T, et al. 2022. Ascertaining death events in a pragmatic clinical trial: insights from the TRANSFORM-HF trial. J Card Fail. S1071916422000549. doi:10.1016/j.cardfail.2022.01.020. PMID: 35181553.
Fellegi IP, Sunter AB. 1969. A theory for record linkage. J Am Stat Assoc. 64(328):1183-1210. doi:10.1080/01621459.1969.10501049.
Hammill BG, Hernandez AF, Peterson ED, Fonarow GC, Schulman KA, Curtis LH. 2009. Linking inpatient clinical registry data to Medicare claims data using indirect identifiers. Am Heart J. 157(6):995–1000. doi:10.1016/j.ahj.2009.04.002. PMID: 19464409.
Lauer MS, Blackstone EH, Young JB, Topol EJ. 1999. Cause of death in clinical research: Time for a reassessment? J Am Coll Cardiol. 34(3):618–620. doi:https://doi.org/10.1016/S0735-1097(99)00250-8. PMID: 10483939.
Lloyd-Jones DM, Martin DO, Larson MG, Levy D. 1998. Accuracy of death certificates for coding coronary heart disease as the cause of death. Ann Intern Med. 129(12):1020–1026. doi:10.7326/0003-4819-129-12-199812150-00005. PMID: 9867756.
National Center for Health Statistics. National Death Index. https://www.cdc.gov/nchs/ndi/. Accessed June 17, 2018.
National Research Council. 2009. Vital Statistics: Summary of a Workshop. Washington, DC: National Academies Press. doi:10.17226/12714. PMID: 25032356.
National Technical Information Service. 2011. Important Notice: Change in Public Death Master File Records. https://classic.ntis.gov/assets/pdf/import-change-dmf.pdf. Accessed June 17, 2018.
Death Information in the Research Identifiable Medicare Data | ResDAC. https://resdac.org/articles/death-information-research-identifiable-medicare-data. Accessed August 24, 2022.
Social Security Administration. 1983. Compilation of the Social Security Laws. https://www.ssa.gov/OP_Home/ssact/title02/0205.htm. Accessed June 17, 2018.
Navar AM, Peterson ED, Steen DL, et al. 2019. Evaluation of mortality data from the Social Security Administration Death Master File for Clinical Research. JAMA Cardiol. 4(4):375-379. doi:10.1001/jamacardio.2019.0198 PMID: 30840023.
Young JC, Pack C, Gibson TB, et al. 2021. Machine learning can unlock insights into mortality. JMIR Public Health & Surveillance. 111(Suppl 2):S65–S68. doi: 10.2105/AJPH.2021.306418. PMID: 34314195.
Warren JR, Milesi C, Grigorian K, Humphries M, Muller C, Grodsky E. 2017. Do inferences about mortality rates and disparities vary by source of mortality information? Ann Epidemiol. 27(2):121–127. doi:10.1016/j.annepidem.2016.11.003. PMID: 27964929.